python yellowbrickの使い方
概要
- 可視化ライブラリ
- seabornやmatplotlibに比べてより機械学習に特化した可視化を行うことができる
インストール
$ pip install yellowbrick
Rank2D
- 特徴量の相関を可視化する
import pandas as pd
from yellowbrick.datasets import load_bikeshare
X, y = load_bikeshare()
from yellowbrick.features import Rank2D
visualizer = Rank2D(algorithm="pearson")
visualizer.fit_transform(X)
visualizer.show()
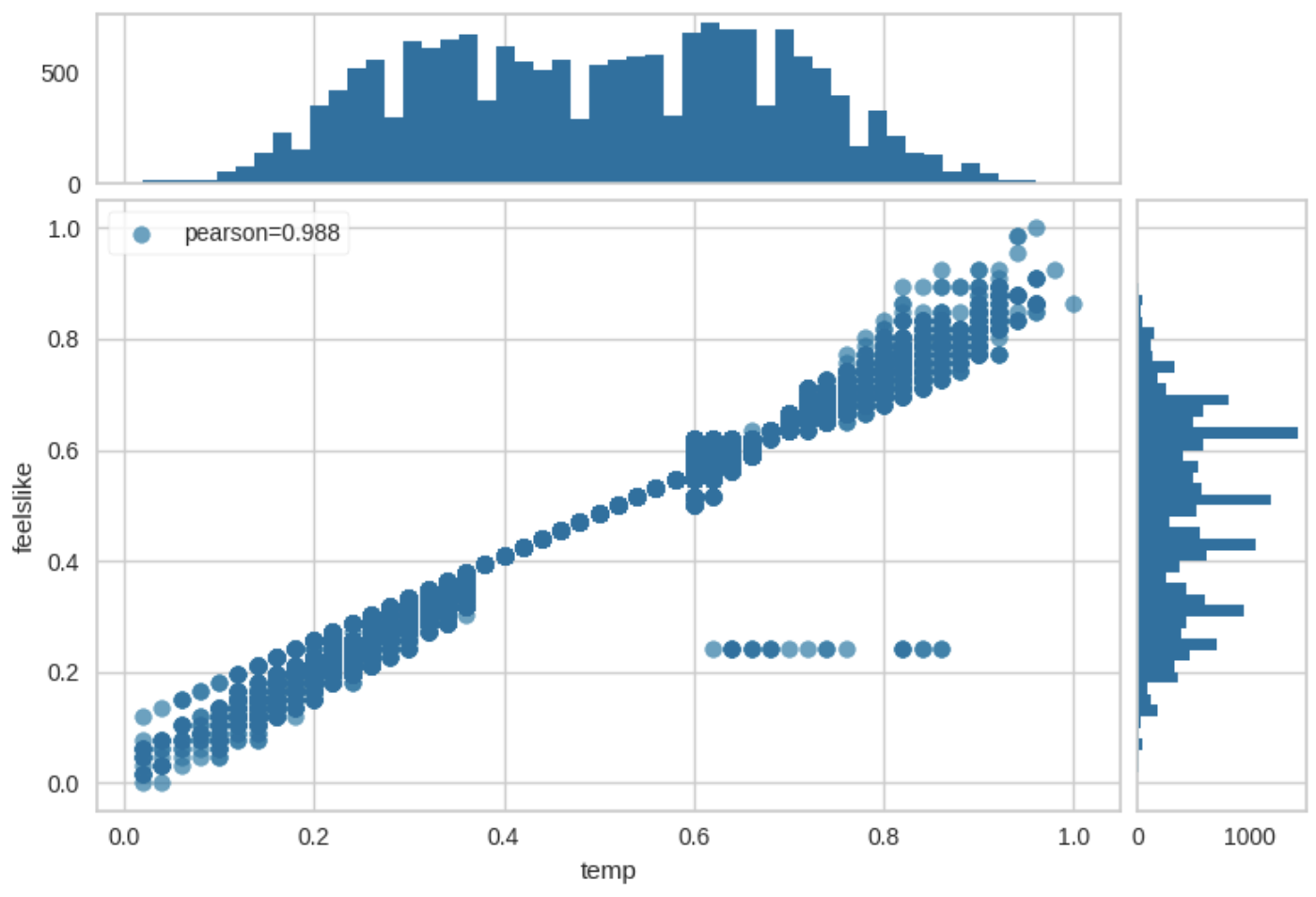
JointPlot
- 相関とヒストグラムを同時に可視化する
from yellowbrick.features import JointPlotVisualizer
visualizer = JointPlotVisualizer(columns=['temp', 'feelslike'])
visualizer.fit_transform(X, y)
visualizer.show()
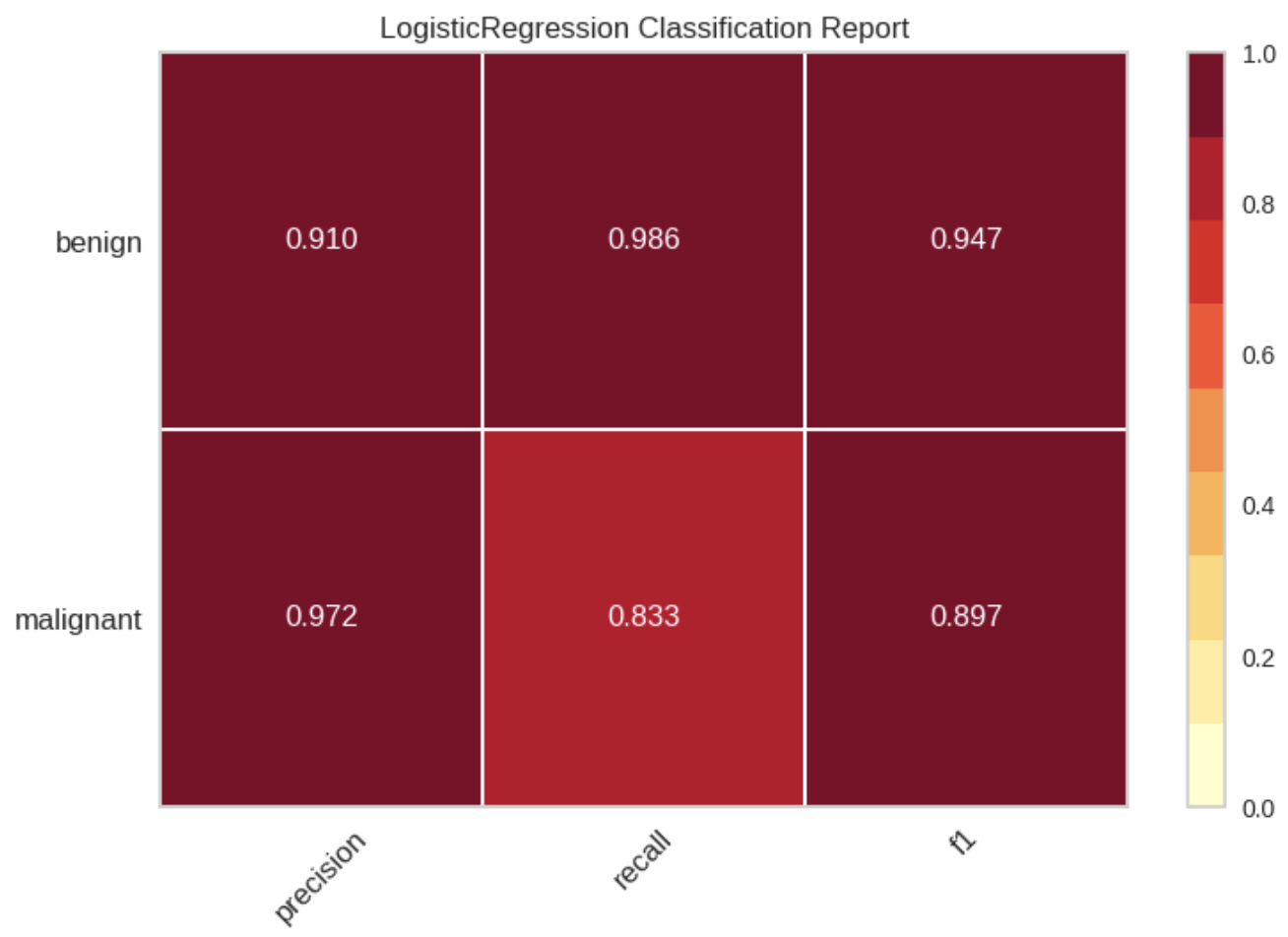
ClassificationReport
- 分類問題の評価指標を可視化する
from yellowbrick.classifier import ClassificationReport
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
# 乳がんデータセットのロード
data = load_breast_cancer()
X, y = data.data, data.target
# データを訓練セットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# モデルの初期化
model = LogisticRegression(max_iter=10**5)
# 分類レポートの視覚化
visualizer = ClassificationReport(model, classes=data.target_names)
visualizer.fit(X_train, y_train) # 訓練データでモデルを訓練
visualizer.score(X_test, y_test) # テストデータでモデルを評価
visualizer.show() # 図の表示
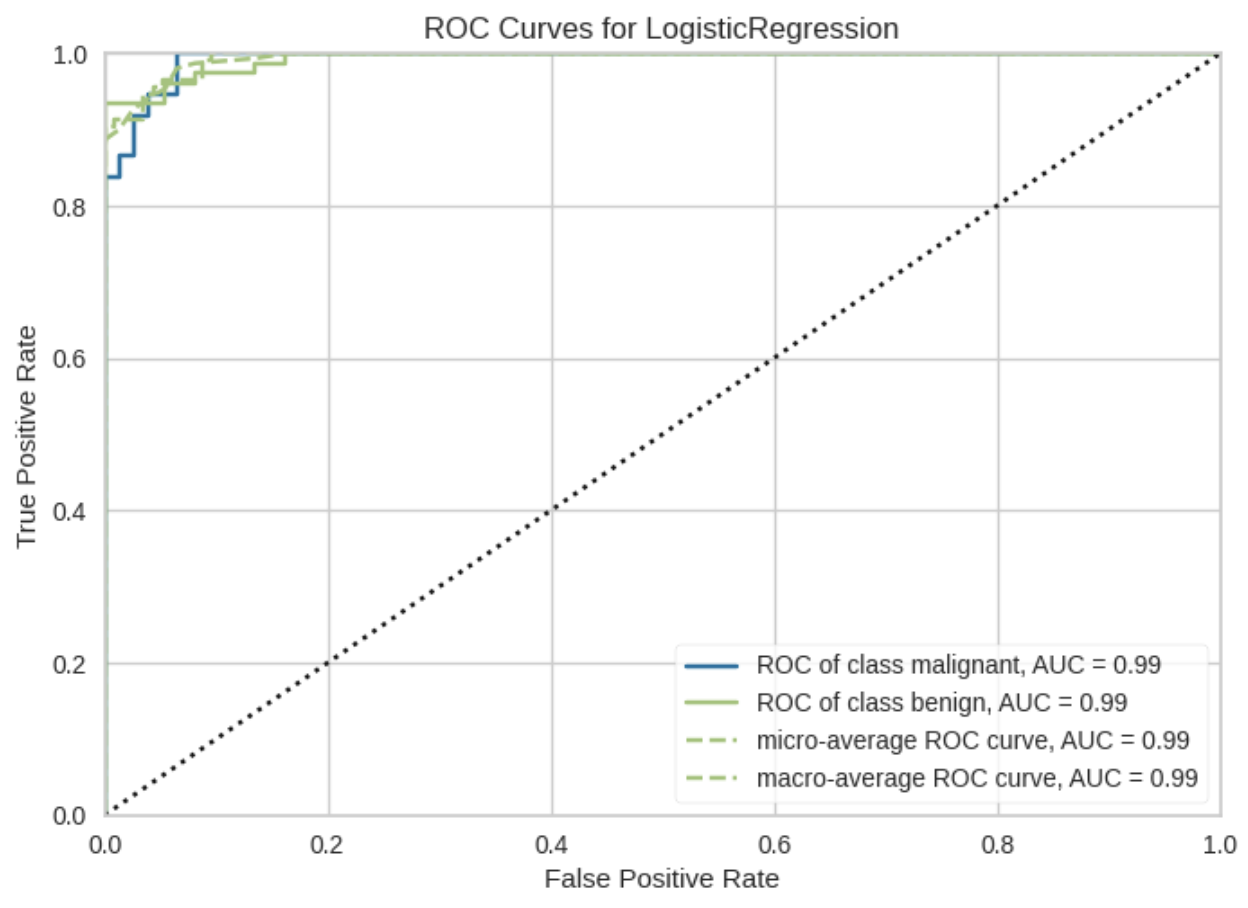
ROCAUC
- ROC曲線を可視化する
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from yellowbrick.classifier import ClassificationReport, ROCAUC
# 乳がんデータセットのロード
data = load_breast_cancer()
X, y = data.data, data.target
# データを訓練セットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# モデルの初期化
model = LogisticRegression(max_iter=10**5)
# ROC曲線の視覚化
roc_auc = ROCAUC(model, classes=data.target_names)
roc_auc.fit(X_train, y_train) # 同じく訓練データでモデルを訓練
roc_auc.score(X_test, y_test) # テストデータでモデルを評価
roc_auc.show() # 図の表示