cbowについて
概要
- ある単語の周辺の単語情報から中央にある単語を予測する問題
- word2vecなどがこれを元にモデルを制作する
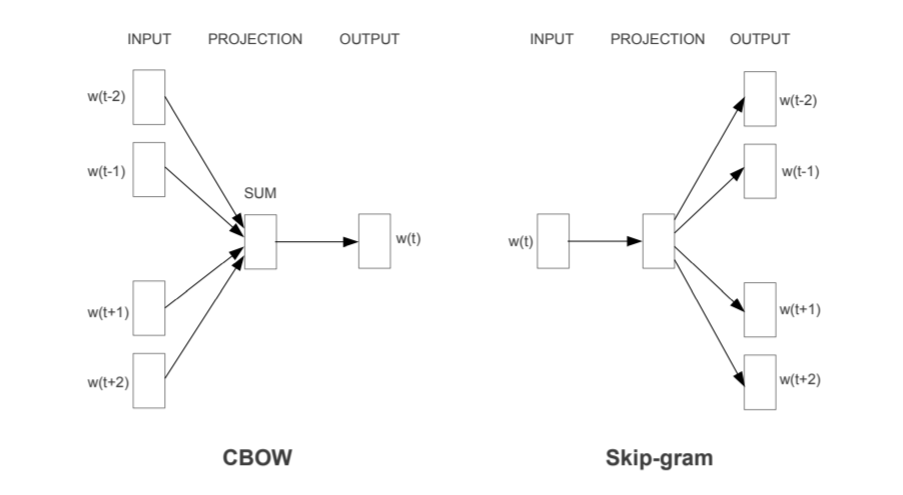
pythonのスクラッチ
データのジェネレータ
def generate_data(corpus, window_size, V):
maxlen = window_size*2
for words in corpus:
L = len(words)
for index, word in enumerate(words):
contexts = []
labels = []
s = index - window_size
e = index + window_size + 1
contexts.append([words[i] for i in range(s, e) if 0 <= i < L and i != index])
labels.append(word)
x = sequence.pad_sequences(contexts, maxlen=maxlen) # List[List[int]]
y = np_utils.to_categorical(labels, V) # カテゴリカルデータにする
yield (x, y)
モデル
model = Sequential()
model.add(Embedding(input_dim=V, output_dim=dim, input_length=window_size*2))
model.add(Lambda(lambda x: K.mean(x, axis=1), output_shape=(dim,))) # windowサイズを1に減らすために平均を取る
model.add(Dense(V, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta')
学習
for ite in range(10):
loss = 0.
for x, y in generate_data(corpus, window_size, V):
loss += model.train_on_batch(x, y)
print(ite, loss)
モデルのウェイトを取り出し
f = open('vectors.txt' ,'w')
f.write('{} {}\n'.format(V-1, dim))
vectors = cbow.get_weights()[0]
for word, i in tokenizer.word_index.items():
str_vec = ' '.join(map(str, list(vectors[i, :])))
f.write('{} {}\n'.format(word, str_vec))
f.close()