attention mechanism
date: 2023-06-24 excerpt: attention mechanismについて
attention mechanismについて
概要
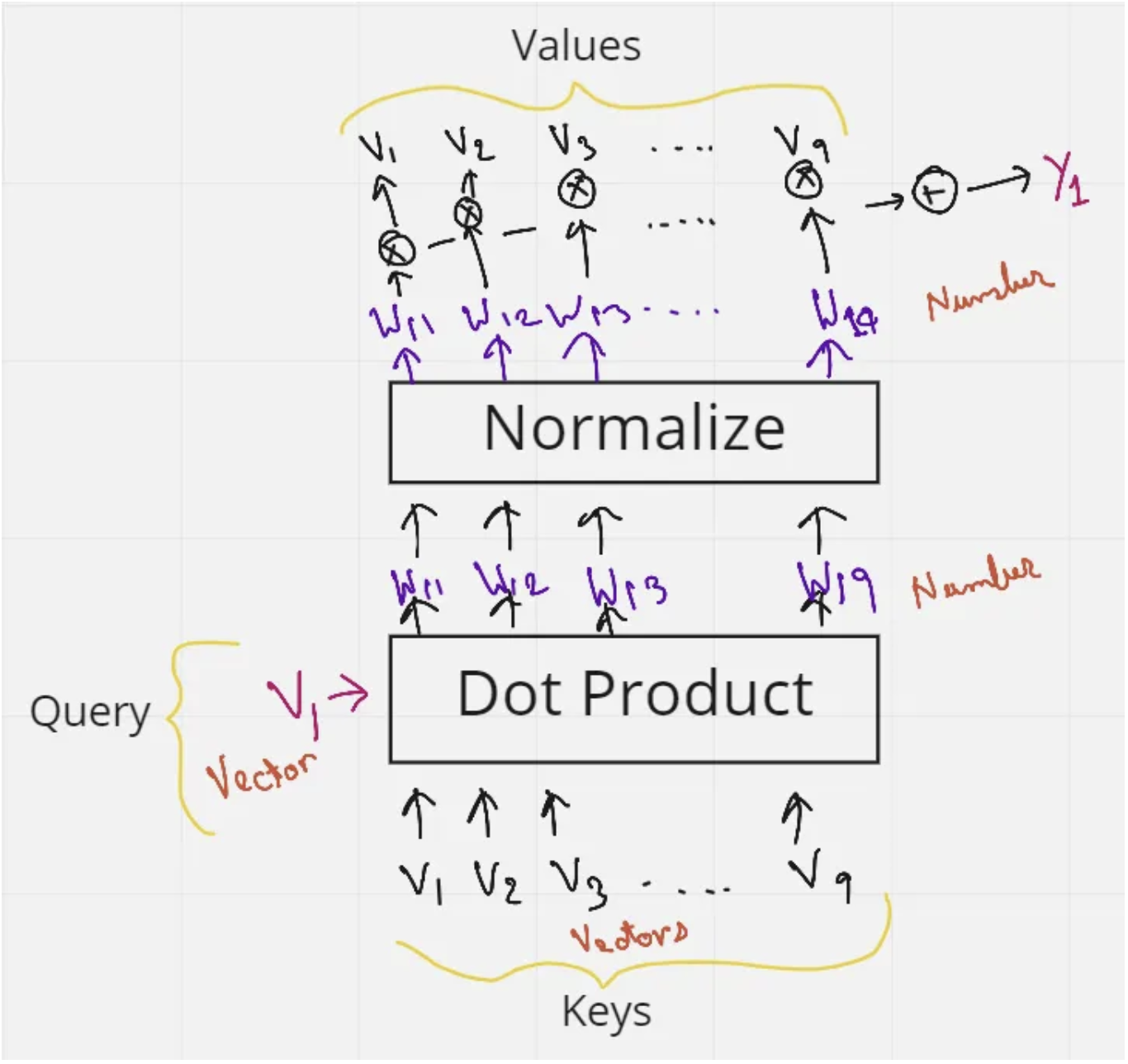
query,key,valueの要素でqueryに対するグローバルなkeyの類似度を考慮できるようにしたもの- RNNの長距離の情報が消えるという側面を解決したもの
- イメージしづらいので、理解をちゃんとするにはイラストが必要
- 類似度のデータベースを想像すると早い
計算プロセス
keyに紐づくvectorがあるqueryもvectorを持つqueryとkey(複数)のvectorの内積を計算する- 内積のsoftmaxを取る
- softmaxした値に対して
valueを掛ける valueをkeyの軸に対してsumする
わかりやすいイラスト
towardsdatascience.comより引用
最小のコード
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleSelfAttention(nn.Module):
def __init__(self, input_dim):
super(SimpleSelfAttention, self).__init__()
# Linear layers for projecting the input to Query, Key and Value
self.query_layer = nn.Linear(input_dim, input_dim)
self.key_layer = nn.Linear(input_dim, input_dim)
self.value_layer = nn.Linear(input_dim, input_dim)
def forward(self, x):
# x is the input and is expected to be of shape (batch_size, sequence_length, input_dim)
# Project the input to Query, Key and Value
Q = self.query_layer(x)
K = self.key_layer(x)
V = self.value_layer(x)
# Calculate the attention scores (QK^T)
scores = torch.matmul(Q, K.transpose(-2, -1)) / (Q.size(-1) ** 0.5)
# Apply the softmax function to the scores
attention_weights = F.softmax(scores, dim=-1)
# Multiply the attention weights with the Value matrix
output = torch.matmul(attention_weights, V)
return output
# Example input (batch_size=2, sequence_length=3, input_dim=4)
x = torch.tensor([[[1.0, 2.0, 3.0, 4.0], [4.0, 3.0, 2.0, 1.0], [1.0, 2.0, 1.0, 1.0]],
[[2.0, 3.0, 4.0, 5.0], [5.0, 4.0, 3.0, 2.0], [2.0, 3.0, 2.0, 2.0]]])
# Initialize the SimpleSelfAttention module
attention_module = SimpleSelfAttention(input_dim=4)
# Forward pass
output = attention_module(x)
print("Output:")
print(output)
"""
Output:
tensor([[[-0.5821, -0.2938, -0.7142, 1.5239],
[-0.4740, -0.4387, -0.6276, 1.5390],
[-0.6427, -0.2540, -0.7910, 1.5553]],
[[-0.8212, -0.5163, -0.9790, 2.1257],
[-0.7534, -0.6272, -0.9384, 2.1545],
[-0.8494, -0.5060, -1.0203, 2.1482]]], grad_fn=<UnsafeViewBackward0>)
"""