NMF
date: 2022-10-04 excerpt: NMF(non-negative matrix factorization)の使い方
NMF(non-negative matrix factorization)の使い方
概要
- Matrix Factorizationのウェイトをマイナスに取れないように制約したもの
- NMFには定数項が存在しないので、すべて0の行であれば、レコメンド結果も0になる
- コンポーネント数にも関連するが、少ないデータでも十分量にレコメンド可能
- 潜在空間はユーザとアイテムの内積であるが、相性とも考えられる
- 内積以外でも、近傍探索や、距離を用いても良い
具体例
from sklearn.decomposition import NMF
import scipy.sparse as sparse
iidxs, jidxs, values = [], [], []
# item購入
for item_id, user_id in zip(train["item_id"], train["user_id"]):
iidxs.append(item_id)
jidxs.append(user_id)
values.append(1) # ウェイトを自由に変えることができる
# スパースマトリックスの構築
X = sparse.csr_matrix((values, (iidxs, jidxs)), shape=(train["item_id"].max()+1, train["user_id"].max()+1), dtype=float)
logger.info('NMFモデルを構築しています...')
model = NMF(n_components=50, init='random', random_state=0, max_iter=500)
model.fit(X)
logger.info('推論を行っています...')
W = model.transform(X)
H = model.components_
# どのitemがどのユーザに適しているかがわkる
preds_raw = W@H
ユーザがどのクラスに属するかを確認する
- 学習したモデルでデータを変換し、最も寄与しているクラスタを確認することができる
W = model.transform(X)
# 各サンプルが最も寄与しているコンポーネントの番号をクラスタとして割り当てる
cluster_assignments = np.argmax(W, axis=1)
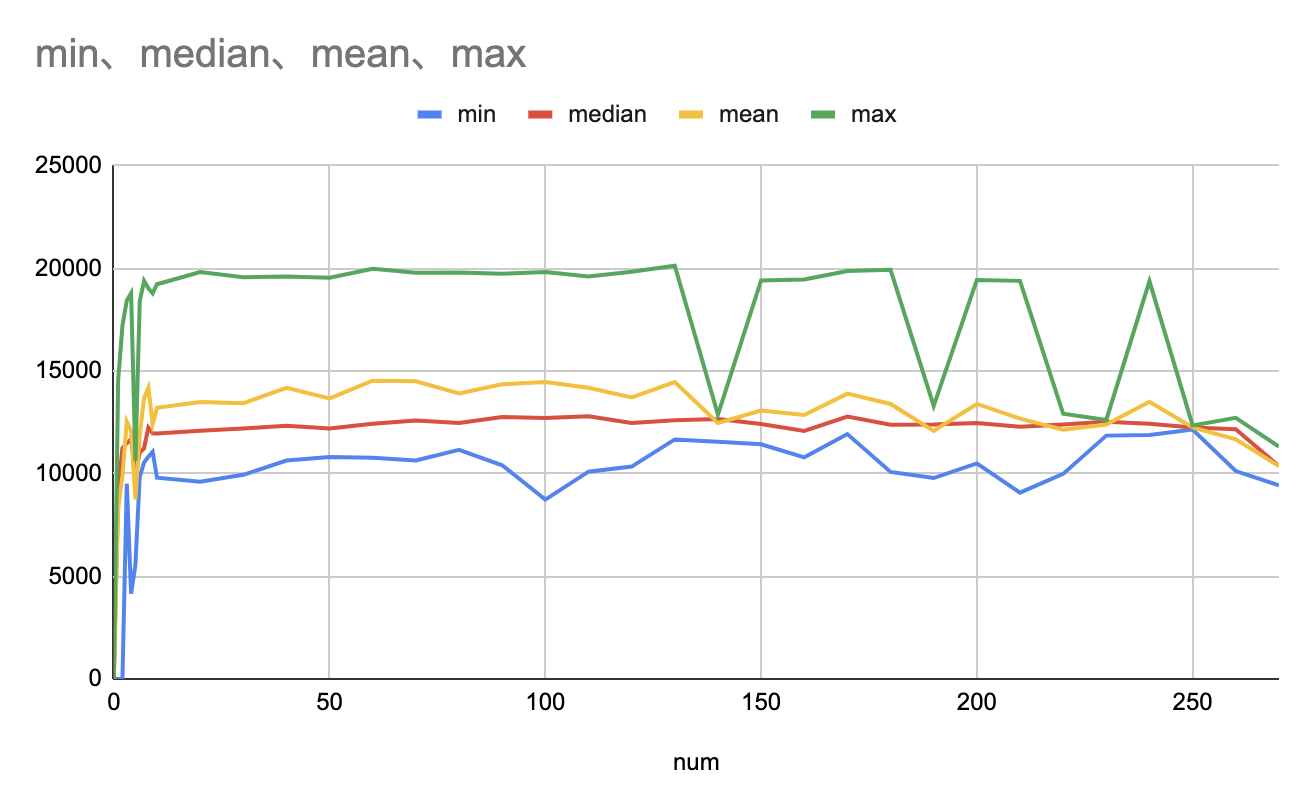
説明変数にいくつデータが有れば十分にレコメンドできるか
- 命題
- 十分にレコメンドできる <=> NMFの結果が0でない
- 確認方法
- modelと学習データを用意し、データの数でソートして、各数でどの程度のレコメンドを行えるか
import pickle
import numpy as np
from typing import Optional
import warnings
warnings.filterwarnings("ignore")
from tqdm.auto import tqdm
import pandas as pd
from dataclasses import dataclass
@dataclass
class Datum:
user_id: int
num: int
x: np.matrix
predict_num: Optional[int]
def calc_model_predict():
with open("../model_X.pkl", "rb") as fp:
model, X = pickle.load(fp)
X = X.todense()
print(X.shape)
lst = []
for item_id, num in enumerate(np.asarray(X.astype(bool).sum(axis=1)).flatten()):
lst.append(Datum(item_id, num, X[item_id], None))
lst.sort(key=lambda x:x.num)
data = []
for datum in tqdm(lst[::-1]):
W = model.transform(datum.x)
H = model.components_
preds_raw = W@H
datum.predict_num = preds_raw.astype(bool).sum()
data.append(datum)
data = pd.DataFrame(data)
data.drop(columns=["x"], inplace=True)
data.to_csv("model_predict.csv", index=False)
def calc_min_mean_max():
df = pd.read_csv("model_predict.csv")
df["num"] = df["num"].apply(lambda x: x if x < 10 else (x // 10)*10)
df = df.groupby(by=["num"]).agg(min=("predict_num", "min"), median=("predict_num", "median"), mean=("predict_num", "mean"), max=("predict_num", "max")).reset_index()
print(df.to_csv("min_mean_max.csv", index=False))
if __name__ == "__main__":
calc_model_predict()
calc_min_mean_max()